Kiriakos Krastillis's Blog
How The Spectrum Pool [SPEC] gets deployed
A single bad version of software should not bring down your operation
As already known, the technical design of SPEC is based on the idea of diversity and robustness. We don't just deploy the official cardano-node docker images. We build two images from scratch, one based on Debian and one based on Nix. While the Nix script is closely similar to the IOHK nix build, the Debian image is completely custom and very "sourcy". This means that on the Deb container we compile everything from source ghc, cabal, cardano-node(!).
So in the end we turn out with a set of docker containers:
- Deb + GHC version + Cardano-Node version
- Nix + GHC version + Cardano-Node version
But only compiling two versions is not enough, you want to make sure your x nodes (8 for SPEC mainnet) don't all update to the same version at the same time. Ideally you want to introduce new versions to your deployment step by step and have enough time between updating individual nodes.
For SPEC this happens through a scheduled ansible run. The run happens every second day and only ever updates a small number of nodes each run (1 or 2 nodes every two days). There are ways to run a system update on all nodes simultaneously or even to deploy a single cardano-node version to all nodes simultaneously, but those methods are only used in case of a critical event that requires instant response.
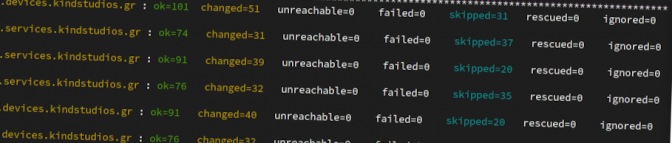
If the system is left on autopilot it will take a little bit more than one week to get all nodes on the newest version. The last nodes to be updated are always the Standby Block Producer and one dark relay. (Note to self: write about the importance of dark relays)
This ensures that, in case of something going wrong at epoch change, there already is one Block Producer and one Relay synced up with the network to continue the operation and ensure near 100% uptime.
In the end, a successful, saturated pool won't bring you that much if it is down all the time. So make sure to pick pools that are set up to be around even in the worst case ;-)
Cheers, K